Serverside Tracking als Hilfsmittel gegen teure Bot-Klicks
![]()
Unser Artikel basiert auf einer Auswertung von Erstzugriffen (Erstbesuchern) auf unsere Unternehmens-Webseite im Zeitraum September und Oktober 2025, erfasst mit unserem Serverside Tracking Tool. Anschliessend diskutieren wir die Auswirkung des zunehmenden Bot Traffics auf Google Ads Kampangnen, Budget und Umwelt.
Was unsere serverseitige Auswertung zeigt
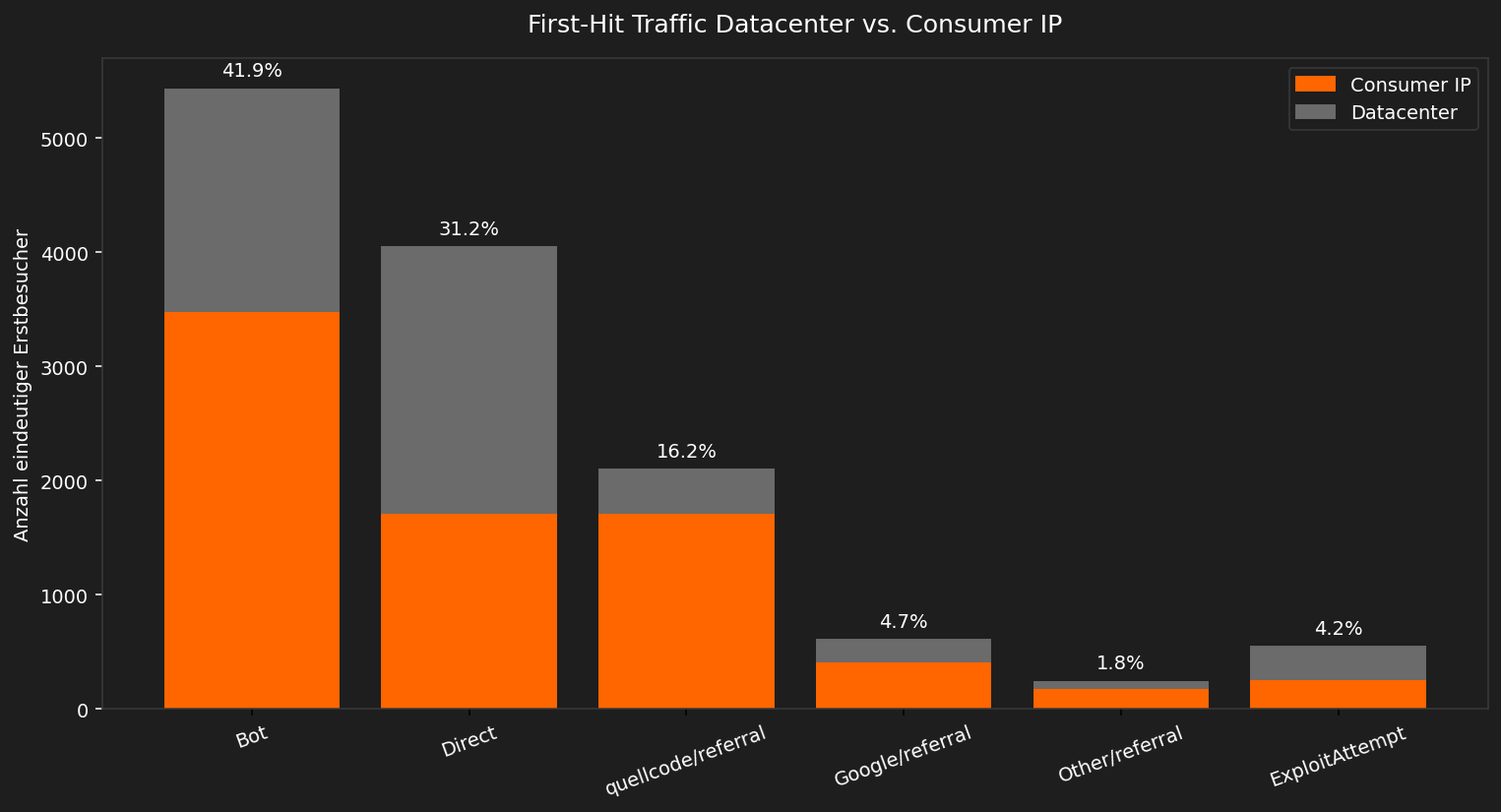
In unserer grafischen Auswertung berücksichtigen wir nur Erstzugriffe, d.h. pro IP und Kalendertag zählt nur der erste Aufruf der Landingpage auf www.quellcode.gmbh. Auf dieser Basis ergibt sich folgendes Bild: 41.9 % der Erstbesuche sind Bots, die sich auch als solche ausgeben; 31.2 % entfallen auf Direktzugriffe ohne Referrer, was auf verschleierte Bot-Zugriffe hindeutet (sehr häufig aus Datacentern). 16.2 % der Erstbesuche tragen eine widersprüchliche Herkunftsangabe (quellcode.gmbh/referral) – ebenfalls ein Bot-Indiz und 4.2 % der Erstbesucher sind automatisierte Exploit-Versuch - also Zugriffe die aktiv nach Schwachstellen suchen. Damit ergibt sich folgendes Bild: Von allen Bot-Zugriffen lassen sich 55 Prozent auf Bad Bots zurückführen und lediglich 45 Prozent der Bots weisen sich auch als solche aus. Der Bad Bot Anteil ist damit sehr hoch, aber im Vergleich zum Imperva Bad Bot Report 2024, der auf etwa 66 Prozent Bad Bot Anteil kommt, sogar noch relativ gering.
Reale Besucher sind die Minderheit: 4.7 % kommen über Google/referral und nur 1.8 % lassen sich auf andere echte Quellen zurückführen.
Warum Bots Kosten verursachen und CO₂ Emissionen erhöhen
Webseitenbesuche werden also mittlerweise zum allergrössten Teil durch automatisierte Bots und nicht durch menschliche User ausgelöst. Das wirkt sich direkt auf die gemessen Werte in Google Analytics 4 (GA4) und unter Umständen auch bei Google Ads (sic) aus. Aufrufe, Klicks, Absprungraten, Sitzungsdauer, Events und Conversions werden verfälscht, und damit sind genau jene KPIs betroffen, die für Steuerung, Attribution und Budgetentscheidungen genutzt werden. Mehr Bot-Last bedeutet zudem höhere Hosting-Kosten, da viele Tarife traffic- oder requestbasiert sind. Damit ist Bot Traffic mittlerweile für den Grossteil der CO₂-Last des Internets verantwortlich. An anderer Stelle erklären wir was man tun kann, um sein eigenes Webseiten-CO₂-Emissionsbudget zu verbessern. Unsere eigene Webseite zählt nachweislich zu den Top 5 % emissionsarmer Webseiten!
Konkrete Massnahmen gegen Bot-Traffic
Es gibt nicht die eine Wunderlösung – wir kombinieren mehrere Bausteine.
Erstens setzen wir auf eine Web Application Firewall (WAF). Sie erkennt typische Muster von Bots (z. B. wiederholte Zugriffe in Sekundenabständen,
auffällige Pfade wie /.env oder /wp-login) und bremst sie mit Rate-Limiting (Anfragen begrenzen).
Die WAF nutzt sowohl „Signaturen“ (bekannte Erkennungsmerkmale) als auch Heuristiken (Verhaltensregeln), um verdächtige Aufrufe früh zu stoppen.
Zweitens pflegen wir die robots.txt und sogenannte Crawler-Hints. Seriöse Crawler (Google, Bing & Co.) halten sich daran;
wir erlauben ihnen gezielt den Zugriff und weisen unerwünschte Bereiche aus. Das reduziert die „guten“ Crawler auf das Nötige und macht Missbrauch auffälliger.
(Teilweise ignorieren „Bad Bots“ diese Regeln – genau dafür braucht es die WAF und weitere Filter.)
Drittens halten wir GA4 (Google Analytics 4) so sauber wie möglich: Wir filtern bekannte Bot-Netze, interne IPs und prüfen Ereignisse, die über das Measurement Protocol (eine Schnittstelle zum Einsenden von GA4-Events) eingehen. Ziel ist, KPIs wie Aufrufe, Klicks, Absprungraten, Sitzungsdauern, Events und Conversions getrennt nach verifizierten und ungeprüften Quellen zu betrachten – so werden Reports wieder belastbar.
Viertens setzen wir auf Honeypots (Lockvogel-URLs, die echte Nutzer nie anklicken) und strikte Security-Header. Treffen Bots diese Fallen, liefern wir bewusst keine Erfolgsmeldungen der HTTP-Statusklasse 2xx, sondern z. B. 403 (verboten) oder 410 (gelöscht) mit minimalen Antwortgrössen. So erhöhen wir die Hürde für automatisierte Scans und vermeiden gleichzeitig „falsche“ Erfolgs-Signale in den Logs.
Fünftens arbeiten wir mit IP/ASN-Massnahmen. ASN steht für Autonomous System Number – damit sind ganze Netze/Provider identifizierbar (z. B. grosse Rechenzentren). Auffällige Netze drosseln wir (Throttling) oder blockieren sie gezielt, besonders wenn viele kurze Sitzungen und hohe Request-Raten auftreten. Das reduziert Kosten (Traffic, CPU, CDN) und schont das CO₂-Budget, weil unnötige Anfragen gar nicht erst durch die Anwendung laufen.
Warum Serverside Tracking der Hebel ist
Der gemeinsame Nenner: Serverside Tracking. Erst wenn wir am Servereingang sehen, was wirklich passiert,
können WAF-Regeln, robots.txt/Crawler-Hints, GA4-Filter, Honeypots und IP/ASN-Kontrollen sinnvoll zusammenspielen – und damit KPIs bereinigen,
Werbebudgets schützen und Infrastruktur- sowie CO₂-Kosten senken.
Unser Leistungsangebot
Unsere Ergebnisse bestätigen die Relevanz von Serverside Tracking und Bot-Filterung. Als Teil unserer Web-Dienstleistungen bieten wir Serverside Tracking als Tool an, und zwar datenschutzkonform, mit Bot- und Exploit-Filter und Datacenter-Erkennung. Auf Wunsch ergänzen wir ein CO₂-Monitoring. So beruhen Entscheidungen wieder auf echten Besuchern – bei geringeren Kosten und kleinerem CO₂-Fussabdruck.
